A row is assigned to a particular AMP based on the primary index value. Teradata uses hashing algorithm to determine which AMP gets the row.
Following is a high level diagram on hashing algorithm.
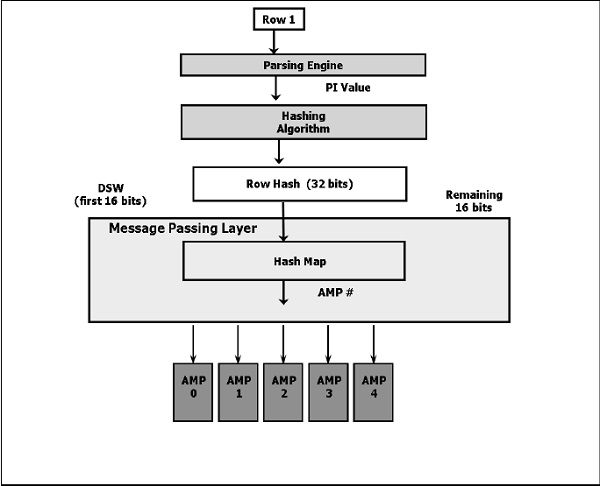
Following are the steps to insert the data.
- The client submits a query.
- The parser receives the query and passes the PI value of the record to the hashing algorithm.
- The hashing algorithm hashes the primary index value and returns a 32 bit number, called Row Hash.
- The higher order bits of the row hash (first 16 bits) is used to identify the hash map entry. The hash map contains one AMP #. Hash map is an array of buckets which contains specific AMP #.
- BYNET sends the data to the identified AMP.
- AMP uses the 32 bit Row hash to locate the row within its disk.
- If there is any record with same row hash, then it increments the uniqueness ID which is a 32 bit number. For new row hash, uniqueness ID is assigned as 1 and incremented whenever a record with same row hash is inserted.
- The combination of Row hash and Uniqueness ID is called as Row ID.
- Row ID prefixes each record in the disk.
- Each table row in the AMP is logically sorted by their Row IDs.
How Tables are Stored
Tables are sorted by their Row ID (Row hash + uniqueness id) and then stored within the AMPs. Row ID is stored with each data row.
| Row Hash | Uniqueness ID | EmployeeNo | FirstName | LastName |
|---|---|---|---|---|
| 2A01 2611 | 0000 0001 | 101 | Mike | James |
| 2A01 2612 | 0000 0001 | 104 | Alex | Stuart |
| 2A01 2613 | 0000 0001 | 102 | Robert | Williams |
| 2A01 2614 | 0000 0001 | 105 | Robert | James |
| 2A01 2615 | 0000 0001 | 103 | Peter | Paul |